⌂ : Coaldigger :
Coaldigger is a free software available on my Gitlab.
Coaldigger is a web scraper, looking for and storing articles from news aggregators such as Google News. The aggregators and the websites hosting the articles are indentified as "mines" in the code of Coaldigger. Every known mine has some "extractors" which are tools used to parse the source of the webpages coming from the mine. An extractor can extract links to other mines (in case of news aggregators) or extract the content to be stored in the database (in case of articles).
In addition to the scraping, Coaldigger tries to analyse and deduce other informations (eg. image processing or semantic analysis) from the downloaded articles in a separate process, using small programs called "refiners". One can add a new refiner any time without restarting Coaldigger. When a new refiner is detected, it is applied on all the data already in the database. Once this is done, it is applied only on new incoming data.
An instance of Coaldigger is running live since January 2014 at http://coaldig.com. The only aggregator it knows is Google News Belgium. It has downloaded more or less 476.000 articles and 395.000 images.
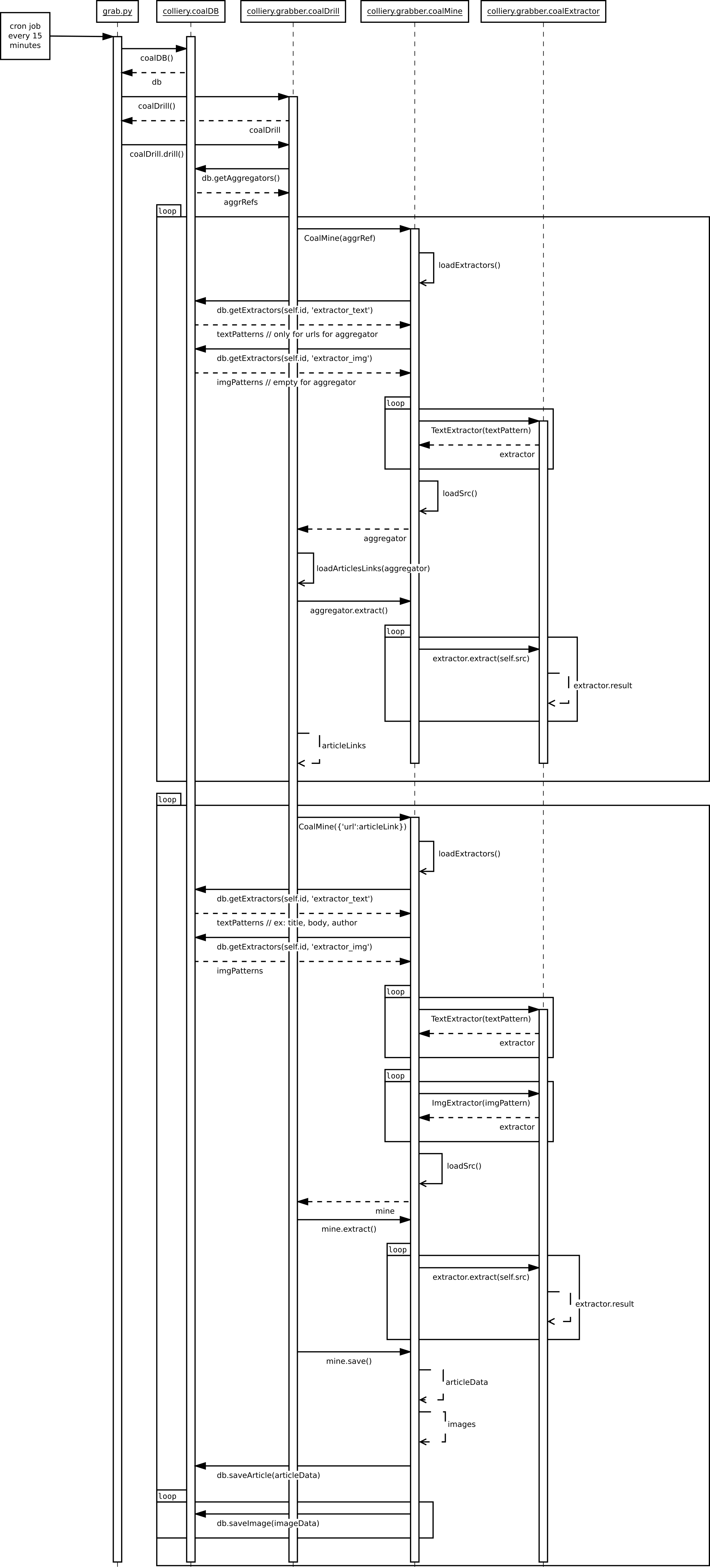
Coaldigger | Sequence diagram